
새로새록
2004-2020 변화한 것들.pandas 본문
csv 파일 분석하면서...연습한 것들 정리
참고로 정권은
2004-07 노무현
2008-12 이명박
2013-16 박근혜
2017-20 문재인임.
전국초중등학교위치표준데이터
import pandas as pd
import numpy as np
import folium
import seaborn as sns
import matplotlib.pyplot as plt
sns.set(font='Malgun gothic')df = pd.read_csv('전국초중등학교위치표준데이터.csv', encoding='euc-kr')
df2 = df.filter(['학교명', '학교급구분', '소재지도로명주소', '위도', '경도'])
# 서울시의 초등학교만 추출
df3 = df2.loc[ (df2['학교급구분'] == '초등학교') ]
df4 = df2.loc[ (df2['학교급구분'] == '중학교') ]# 지도 객체 생성
# zoom_start: 배율 1~22
map_osm = folium.Map(location=[37.566651, 126.978428], zoom_start=12)
# 데이터프레임의 행수 만큼 반복하면서 마커생성
for i in df3.index:
# 행 우선 접근 방식으로 값 추출하기
name = df3.loc[i, '학교명']
lat = df3.loc[i, '위도']
lng = df3.loc[i, '경도']
# 추출한 정보를 지도에 표시
marker = folium.Marker([lat,lng], popup=name)
marker.add_to(map_osm)
# 데이터프레임의 행수 만큼 반복하면서 마커생성
for i in df4.index:
# 행 우선 접근 방식으로 값 추출하기
name = df4.loc[i, '학교명']
lat = df4.loc[i, '위도']
lng = df4.loc[i, '경도']
# 추출한 정보를 지도에 표시
marker = folium.Marker([lat,lng], popup=name)
marker.add_to(map_osm)
map_osm
Make this Notebook Trusted to load map: File -> Trust Notebook

단, csv에 생략된 학교가 많아, 확인해서 초중고 합쳐서 만들고 다른 자료를 찾음.
2004-2020년간 서울 구별
유치원 초등학교 중학교 고등학교 <학생수/학급수/학급당 학생수>
df2 = pd.read_excel('rerport.xls')
df2
df3 = df2.loc[:, ['기간','지역','유치원','초등학교','중학교','고등학교']]
df3.drop(index=[0,1], axis=0, inplace=True)2004/2020년도 구별 비교 - 유치원.초중고등학생생수
공통점: 유치원 원아수 <중,고등학교 학생수 <초등학교 학생수


df_20[2:].groupby(['지역']).sum().plot(figsize=(15,8))
plt.ylim([0, 60000])
코드는 좀 생략하고 한개만 예시로 가져오겠음.
년도별 유치원생수
df3_t = df3[df3['지역']=='합계']
sns.relplot(x="기간", y="유치원", data=df3_t, height=8)
plt.ylim([0,100000])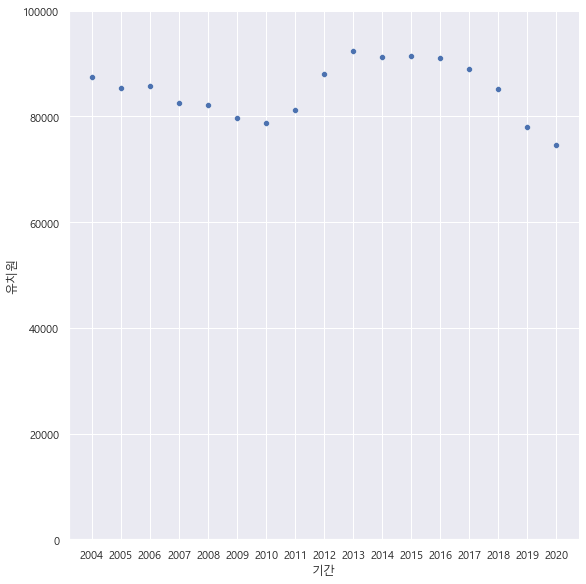
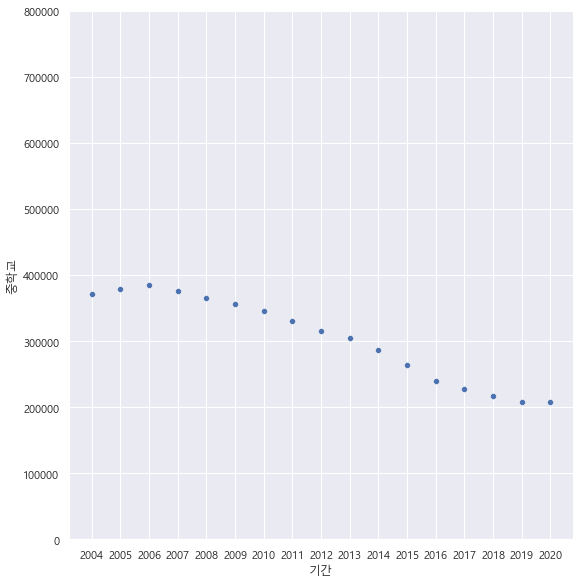
년도별 초등학교/중학교/고등학교


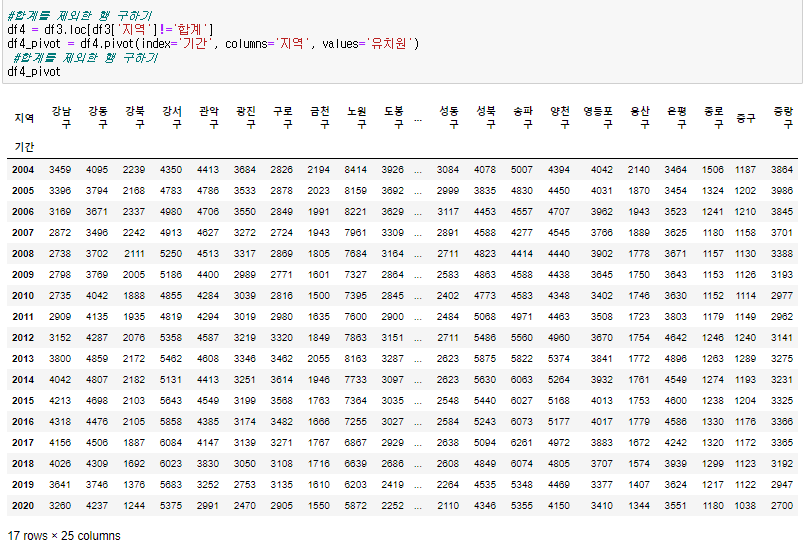
피벗테이블 만들기 ☆_★
예시


df_pivot = df.pivot(index='기간', columns='지역', values='유치원')
y축기준 참고:
>초등학생은 1-6학년이라 범위 : 8만명
>중고등학생은 1-3학년이라 범위: 4만명(반으로 쪼갬)
>유치원생은 워낙 적어서 범위를 1만명으로 설정해서 만듦
- 해석: 아이들은 보통 어린이집/유치원 으로 나뉘며 나이기준이 5,6,7세라는 애매함이 있어서 인지 적었음.


▲초등학교 plt.ylim([0, 80000])
▽ 중학교 고등학교 plt.ylim([0, 40000])


중고등학교 진학넘버가 좀더 증가하는 걸로 보아,
고등학교를 서울로 보내고자 하는 경향이 있다는 걸 확인 할 수 있었음
유입-유출 >0 임.
(유출은 특목고, 높은 자사고 등이 서울외곽 지역 + 기타 이유들로 갔을 것임을 유추 )
(유입은 일반고는 평균적으로 타지역보다 서울이 좀더 높은 성적 + 기타이유들로 전입해옴을 유추)
이게 시각화가 제대로 안된것 같아서,
df4=df4_pivot.transpose()
df4.columns = df4.columns.str.strip()
df4.sort_values(by=['2004'], axis=0, ascending=False)
해서 표를 다시 만들었음ㅎㅎ 보고싶음 오백원 하나 534~
일인당 국민총소등소과 증가율
df_gdf = pd.read_excel('gdp.xls')
names = list(df_gdf.loc[1, :])
df_gdf.columns=names
df_gdf.dropna(inplace=True)
df_gdf
# 출처 csv: https://www.index.go.kr/unify/idx-info.do?idxCd=4221
"""요기가 은근 깔끔한 데이터가 많았음. 2004-2020까지 가져옴
단, 엑셀->csv 가져올때 멀티인덱스에서 null값이 발생하므로, 표를 한번 다듬어줬음"""

주석: 1) 1인당 실질(명목) 국민총소득= 실질(명목) 국민총소득 ÷ 총인구. 2) 실질 국민총소득은 연평균 물가지수(2015년=100)를 이용하여 산출함. 3) 명목 국민총소득은 명목 GDP에 명목 국외순수취요소소득을 더하여 산출함. 4) 2015년 기준년 개편 국민계정 자료임. 5) 2020년은 잠정치임.
목 GDP란 당해연도의 총생산물을 당해연도의 가격(경상가격)으로 계산한 GDP
실질 GDP란 당해연도의 총생산물을 기준연도의 가격(불변가격)으로 계산한 GDP -->국민경제의 규모
명목/실질 차이 : 출차: 한국은행
명목GDP는 어떤 해의 생산수량에 당해년도 가격을 곱하여 산출하는 거예요. 예를 들어 2006년의 명목GDP는 2006년의 생산된 생산수량에 2006년의 시장가격을 곱하여 산출하죠. 명목GDP는 어떤 해의 생산수량과 가격의 곱으로 나타나므로 생산물의 수량이 늘어나지 않더라도 물가가 상승하면 명목GDP는 증가해요. 예를 들어 2005년에 생산된 재화의 수량과 2006년에 생산된 재화의 수량이 동일하고 2006년이 2005년에 비해 물가만 10% 상승하면 명목GDP는 10% 증가한답니다.
실질GDP는 어떤 해의 생산물에 특정년도의 가격을 곱하여 산출하는데 예를 들어 2000년이 기준년일 때 2006년의 실질GDP는 2006년에 생산된 생산수량에 2000년의 시장가격을 곱하여 산출하지요. 실질GDP는 어떤 해의 생산수량과 특정년도의 가격의 곱으로 나타나므로 물가가 상승하더라도 생산수량이 늘어나지 않으면 실질GDP는 변동하지 않아요. 2005년에 생산된 재화수량과 2006년에 생산된 재화수량이 동일하고 물가만 10% 상승할 경우 명목GDP는 10% 증가하지만 실질GDP는 변동하지 않아요.
--> 명목GDP는 어떤 해의 국가간 GDP를 비교하거나 국민경제에서 각 산업의 비중이 어떻게 변하는가를 분석하는 데 사용되며 실질GDP는 물가상승 효과를 반영하지 않으므로 경제성장, 경기변동 등 국민경제의 규모가 장기적으로 어떻게 변화하는지 알아보는 데 사용된답니다.
GDP디플레이터= 명목 GDP를 실질 GDP로 나누고 100을 곱해 계산한다.
국가지표체계
www.index.go.kr
'소프트웨어융합 > 파이썬 기타.py' 카테고리의 다른 글
| python - opencv: 사진 윤곽선 기본(2) (0) | 2021.09.27 |
|---|---|
| python: opencv: 툴이해 기본(1) (0) | 2021.09.27 |
| pandas - dataframe 복습 사이트 모음 (1) | 2021.09.08 |
| 빅데이터 (0) | 2021.09.02 |
| 빅데이터 (0) | 2021.09.01 |

